Realizing that I’m not alone in this, I have to admit I have become very curious about Data Science. I realize it’s one of the Buzz Word Trifacta (Data Science, Machine Learning, Big Data). But it sounds like both a fascinating field with huge untapped potential and an exciting space where sophisticated hunches meet statistical nuts and bolts (academica!) and a hacker’s skillset is as useful as more conventional database and computing systems experience. It sounds like a cross-disciplinary breeding ground for great ideas and new insights.
It’s especially the notion of uncovering insights hidden from traditional analytical tools or techniques through the use of Machine Learning or Big Data technology. It’s the discovery of patterns you weren’t even looking for or even knew you should consider. I like to speculate on any new project or similar scoping rt what the questions might be that I’m not asking because I don’t know I’m supposed to ask them. The Rumsfeldian unknown Unknowns. Data Science doesn’t provide all those questions and questions. But it can help with identifying some predictive factors.
Granted, you only have to spend a few minutes mulling over the examples of predictive analytics, say in e-commerce, to realize that we’re quickly moving into an age where ethics around capturing, ingesting, and interpreting data is going to be as important as the development of new algorithms. But there is so much potential for these insights helping us with energy efficiency, science and biotech research, agriculture… you name it, that I am hopeful.
 I have a couple of books on my bookshelf that are introductions to the field. “Data Science for Business” by Foster Provost and Tom Fawcett and “Machine Learning” by Peter Flach. There is no doubt which of the two is better suited for bedtime reading – Provost & Fawcett, which is a largely non-technical introduction that focuses on business applications, and which one falls more into the category of textbook – Flach, which is substantially more infused with formulas and their derivations.
I have a couple of books on my bookshelf that are introductions to the field. “Data Science for Business” by Foster Provost and Tom Fawcett and “Machine Learning” by Peter Flach. There is no doubt which of the two is better suited for bedtime reading – Provost & Fawcett, which is a largely non-technical introduction that focuses on business applications, and which one falls more into the category of textbook – Flach, which is substantially more infused with formulas and their derivations.
But I think both are good investments. What strikes me is that the material they cover is very similar – various types of analytical models, types of data classification, segmentation – supervised (when classification has a target) versus unsupervised (where clustering occurs but you may not know why).
is that the material they cover is very similar – various types of analytical models, types of data classification, segmentation – supervised (when classification has a target) versus unsupervised (where clustering occurs but you may not know why).
Provost & Fawcett provide an overview of what’s possible with these techniques, especially for business. Flach focuses on how to do it. So what’s really the difference between the two? I Data Science the discipline and Machine Learning the toolkit?
Since I am always big on definitions, I looked up both Data Science and Machine Learning.
“Data science, also known as data-driven science, is an interdisciplinary field about scientific methods, processes, and systems to extract knowledge or insights from data in various forms, either structured or unstructured, similar to data mining.” (https://en.wikipedia.org/wiki/Data_science)
This definition does not seem to do justice to the recent hype about the sexiness of data science. What’s missing is an emphasis on technology that allows doing things that used to not be possible until very recently, eventhough they might be based in math and statistics.
But then I’m reading on wikipedia that the term “data science” is actually 30 years old. So maybe it’s the buzz factor that is distorting my expectations.
I see Data Science at the intersection of science/math, coding/automation, and understanding of business or other domain’s needs. It’s multi-disciplinary and implies wearing many hats. There was a great analogy to the tasks involved in preparing a meal on this page
https://www.quora.com/What-is-data-science-and-what-is-it-not
It’s a combination of using various skills and knowledge to extract as much knowledge (and meaning?) from data as possible. (There are actually various good contributions on that same page, including a curriculum of what to study if you want to be a data scientist. But I’ll save that for another post.)
So how about Machine Learning? Is it just part of data science, one of the things a Data Scientist does, one of the main things? My butchered quote from Wikipedia…
“Machine learning […] gives ‘computers the ability to learn without being explicitly programmed. (Arthur Samuel)’ …evolved from the study of pattern recognition and computational learning theory in artificial intelligence, […] explores the study and construction of algorithms that can learn from and make predictions on data […] algorithms overcome following strictly static program instructions by making data-driven predictions or decisions […] is employed in a range of computing tasks where designing and programming explicit algorithms with good performance is difficult or infeasible […] ; example applications include email filtering, detecion of network intruders” (https://en.wikipedia.org/wiki/Machine_learning)
Long story short, I think this is a very exciting field simply because it’s so vast, so loosely defined in the disciplines it covers. It heavily leverages the newest technologies and is based in science, without being too academic, it’s all about learning, experimenting, it’s fail fast/learn fast, it’s to statistics what hacking is to programming (ok, now I’m getting poetic and muddying up more definitions).
I would love to find an opportunity to be part of a data science team. So if you got an opening for someone with Python/SQL skills and never fading curiosity, let me know.

 Intel i7-quadcore
Intel i7-quadcore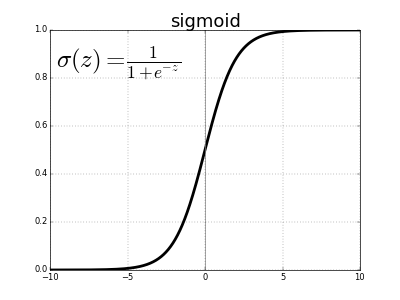 And because you want your input to fall into the range of values where your activation function has significant gradient so the network can learn. For sigmoid that’s somewhere between -3 and +3 (this is me looking at the graph). For more information, see
And because you want your input to fall into the range of values where your activation function has significant gradient so the network can learn. For sigmoid that’s somewhere between -3 and +3 (this is me looking at the graph). For more information, see 